The Difference: Throughput vs Latency
Latency and Throughput are important concepts for data scientists. How are they distinct? And why is this distinction important, not just for technical systems, but also for team performance?


Imagine you have a conveyor belt in a factory that transports widgets from one end to the other:
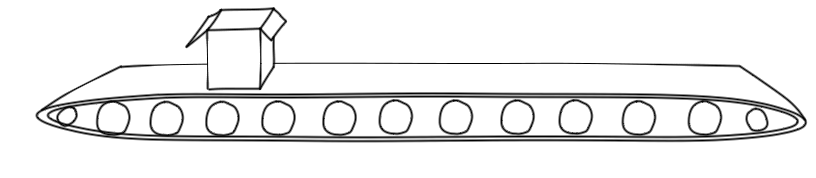
If you speed it up, you’ll reduce (i.e. improve) latency (the time taken for a given widget to pass through):
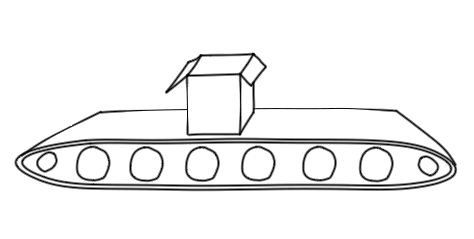
If you widen it, you’ll increase throughput (the number of widgets per second that pass through) - but you won’t improve latency:
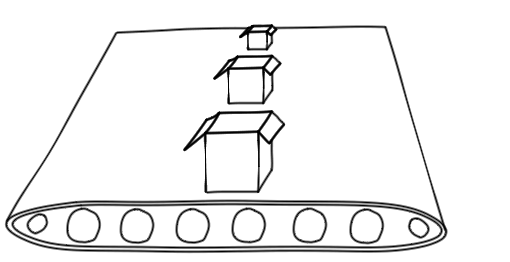
In the case of, say, website performance, latency corresponds to how quickly the page loads (aka ‘performance’). Throughput corresponds to how many users you can have hitting the site concurrently (aka ’scalability’).
Both latency and throughput are important, but users of the system will probably notice latency most, since that’s what’s delaying their task being completed (e.g. page load time).
If you improve latency, you also improve throughput. However, improving throughput won’t improve latency. Imagine making a slow conveyor belt wider - a given widget will still take a long time to pass all the way along it.
It’s often easier to improve throughput than latency for a machine system. For example, scaling the number of webservers (or Spark job executors, or whatever) horizontally will improve throughput but may not improve latency at all.
This distinction also ends up being important for organisational as well as technical system performance reasons.
- What is Machine Learning?
- What is Overfitting?